-
[한기교] SQL 활용 필기(13) - 인덱스와 뷰비전공자 공부일기/:: DB - SQL 2020. 5. 5. 07:48
< 인덱스의 기초 >
ㅁ 인덱스의 개념
- 검색 성능을 향상 시키기 위한 부가적인 자료 구조
- QL 명령문의 검색 속도를 향상시키기 위해 칼럼에 대해 생성하는 객체
- 포인트를 이용하여 테이블에 저장된 데이터를 랜덤 액세스하기 위한 목적으로 사용
* 객체지향 프로그래밍의 참조변수처럼 값이 아닌 주소값을 저장하는 개념
ㅁ 인덱스가 효율적인 경우
- WHERE 절이나 조인 조건절에서 자주 사용되는 칼럼의 경우
- 전체 데이터중에서 10~15%이내의 데이터를 검색하는 경우
- 두 개 이상의 칼럼이 WHERE절이나 조인 조건에서 자주 사용되는 경우
- 테이블에 저장된 데이터의 변경이 드문 경우
--- 색인은 부가적인 자료구조이므로, 데이터 삽입 시 비효율적일 수 있음
--- 인덱스는 실제 데이터가 아닌 값이 저장된 위치정보를 저장하고 있기 때문에,
--- 새로운 데이터가 추가될 때마다 인덱스의 구조도 변경되어야 하기 때문이다.
ㅁ 색인 생성
CREATE INDEX 색인명 ON 테이블명(속성명, 속성명,…)ㅁ 색인 삭제
DROP INDEX 색인명 ON 테이블명< 인덱스의 종류 >
1. 고유 인덱스 vs 비고유 인덱스
ㅁ 고유 인덱스
: 유일 값을 가지는 속성에 대하여 생성하는 색인
- 각 키 값은 테이블의 하나의 튜플과 연관됨
- 고유 인덱스를 생성할 때는 UNIQUE 키워드를 사용함
CREATE UNIQUE INDEX 인덱스명 ON 부서명(속성명)* 기본키
1) 테이블이 기본키에 대해서는 자동으로 고유색인(Primary Index)이 생성됨 *기본키는 중복을 허용하지 않음
2) 새로운 튜플을 삽입할 때마다 키값이 고유값인지 검사해야 함
3) 테이블에 속한 튜플들이 많다면 매우 느림
===> Primary Index 이용 (기본키에 생성되는 고유 색인)
* 관계형 테이블의 검색
1) 테이블 검색 시 기본키만을 사용하지 않음 (ex) 학생 테이블에서 학번이 100번인 학생 검색하기
2) 실제로는 학생을 검색할 때 학번보다 이름을 검색하는 경우가 더 많음
3) 검색을 빨리 하려면 조건에 많이 사용되는 컬럼에 대하여 색인을 생성
===> Secondary Index 이용 (기본키가 아닌 속성에 대해 색인)
ㅁ 비고유 인덱스
: 중복된 값을 가지는 속성에 생성하는 인덱스
- 키 값은 여러 개의 튜플들과 연관됨
- UNIQUE 없이 색인을 생성하면 비고유 색인이 됨
CREATE INDEX 인덱스명 ON 테이블명(위치)2. 단일 인덱스 vs 결합 인덱스
ㅁ 단일 인덱스
: 하나의 속성만으로 구성된 색인
* 고유 인덱스, 비고유 인덱스는 모두 단일 인덱스
ㅁ 결합 인덱스
: 두 개 이상의 속성들에 대하여 생성된 색인
- ON절에 여러 개의 속성명을 쓰게 되면 결합 인덱스가 됨
CREATE INDEX 인덱스명 ON 테이블명 (속성명1, 속성명2)3. DESCENDING INDEX
ㅁ DESCENDING INDEX
- 일반적인 색인들은 속성값에 대하여 오름차순으로 정렬되어 저장되지만,
경우에 따라 내림차순으로 정렬해야 할 때 DESCENDING INDEX 사용
- 특별히 속성별로 정렬 순서를 지정하여 결합 인덱스를 생성하는 방법
- 색인 생성 시에 각 속성별로 정렬순서(DESC, ASC)를 정해줌
CREATE INDEX 인덱스명 ON 테이블명(속성명1 ASC, 속성명2 DESC)4. 집중 인덱스 vs 비집중 인덱스
ㅁ 집중 인덱스
- 테이블의 튜플이 저장 된 물리적 순서 해당 색인의 키값 순서와 동일하게 유지되도록 구성된 색인
- 기본키에 대하여 생성된 색인은 집중 인덱스임
- 테이블의 튜플들이 기본키에 오름차순으로 정렬되어 저장되어 있고 기본키 색인 또한 기본키에 따라서 오름차순으로 정렬되어 있음
- 집중 인덱스는 하나의 테이블에 대하여 하나만 생성할 수 있음!
ㅁ 비집중 인덱스
- 집중 인덱스가 아닌 인덱스들
ㅁ 질의 수행 시 인덱스를 사용하는지 확인하기 ---> 잘 이해 못했음
1) 질의 수행 시 인덱스를 강제로 사용하게 하기
2) employee테이블의 ename을 가지고 색인 emp_name_idx을 만듦
--- 질의 수행기가 해당 색인을 사용하지 않음. 강제로 사용하게 해야 함
3) FROM 절에 WITH(INDEX= INDEX_NAME)을 추가하여 강제로 특정 색인을 사용하게 함
4) 색인을 사용하는지 질의수행 계획 확인
< 뷰의 개념 >
ㅁ 뷰의 개념
- 하나 이상의 기본 테이블이나 다른 뷰를 이용하여 생성되는 가상 테이블
- 기본 테이블은 디스크에 공간이 할당되어 데이터를 저장함
- 뷰는 데이터 딕셔너리(Data Dictionary) 테이블에 뷰에 대한 정의(SQL문)만 저장되어 디스크 저장 공간 할당이 이루어지지 않음
- 전체 데이터 중에서 일부만 접근할 수 있도록 함
- 뷰에 대한 수정 결과는 뷰를 정의한 기본 테이블에 적용됨
- 뷰를 정의한 기본 테이블에서 정의된 무결성 제약조건은 그대로 유지됨
ㅁ 뷰의 필요성
- 사용자 마다 특정 객체만 조회할 수 있도록 할 필요가 있음
--- ex) 모든 직원이 모든 직원에 대한 사원정보를 보면 안 됨!
- 복잡한 질의문을 단순화 할 수 있음
- 데이터의 중복성을 최소화할 수 있음
--- ex) 판매부에 속한 사원들만 따로 테이블로 만들면 사원 테이블과 중복됨 --> 비일관성 --> 뷰 사용으로 해결
ㅁ 뷰의 장점
- 논리적 독립성을 제공함
- 데이터의 접근 제어(보안)
- 사용자의 테이터 관리 단순화
- 여러 사용자의 다양한 데이터 요구 지원
ㅁ 뷰의 단점
- 뷰의 정의 변경 불가
- 삽입, 삭제, 갱신 연산에 제한이 있음
(뷰에 대한 갱신 연산이 허용되면 뷰의 기본 테이블에도 반영)
ㅁ 뷰의 생성 구문
CREATE VIEW 뷰이름 AS SQL문(select 문)ㅁ 뷰의 삭제 구문
DROP VIEW 뷰이름ㅁ 뷰의 종류
- 단순 뷰 : 하나의 기본 테이블 위에 정의된 뷰
- 복합 뷰 : 두 개 이상의 기본 테이블로부터 파생된 뷰 (조인현상 이용)
ㅁ 뷰에 대한 갱신 연산
- 무결성 제약 조건, 표현식, 집단연산, GROUP BY 절의 유무에 따라서 DML문의 사용이 제한적
(ex) *** 사원 테이블에서 평균 연봉을 구하는 뷰 생성 CREATE VIEW EMPAVGSAL AS SELECT AVG(SALARY) AS SALAVG FROM EMPLOYEE *** 평균연봉 뷰에서 평균 연봉 10씩 증가시키기 UPDATE EMPAVGSAL SET SALAVG = SALAVG+10 ===> 오류남. 뷰가 집단연산 결과일 경우, 뷰를 통한 갱신연산 불가능ㅁ 인라인 뷰
: 하나의 질의문 내에서만 생성되어 사용 되어지고 질의문 수행 종료 후에는 사라지는 임시 뷰
- FROM절에서 서브 쿼리를 사용하여 생성하는 임시 뷰
- 뷰의 명시적인 선언(즉, create view 문)이 없음
- FROM 절에서 참조하는 테이블의 크기가 클 경우, 필요한 행과 속성만으로 구성된 집합으로 정의하여 질의문을 효율적으로 구성
- 질의문 수행종료 후 사라지므로, 여러 개의 쿼리문에서 사용해야 하는 뷰라면 CREATE VIEW하는 게 더 효과적일 수 있음
ㅁ WITH 절
: 인라인 뷰의 또 다른 정의 방법
- FROM 절에 임시 질의 결과를 정의하는 대신 WITH 절을 이용하여 임시 테이블을 생성
WITH 임시테이블명(속성명) AS (SELECT ~ FROM ~ WHERE) 본 SQL문 (ex) WITH S(DNO, AVG_SAL) AS(SELECT DNO, AVG(salary) FROM EMPLOYEE GROUP BY DNO) SELECT DNAME, AVG_SAL FROM S, DEPARTMENT D WHERE S.DNO = D.DNOㅁ 뷰의 정의 보기
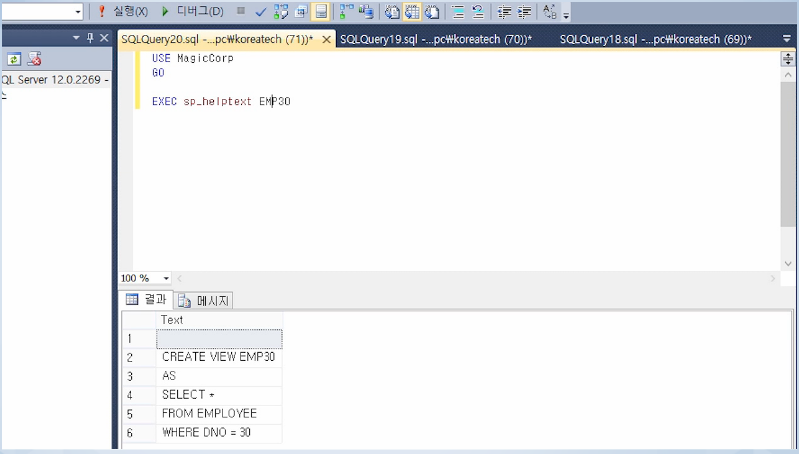
- 뷰의 정의 내용을 보고 싶을 경우
---> SP_HELPTEXT라는 저장 프로시져를 이용함
- 저장 프로시져를 수행하는 명령문
---> EXEC
'비전공자 공부일기 > :: DB - SQL' 카테고리의 다른 글
[한기교] SQL 활용 필기(15) - 저장 프로시저와 사용자 정의 함수(다시듣기) (0) 2020.05.05 [한기교] SQL 활용 필기(14) - 사용자 관리 (0) 2020.05.05 [한기교] SQL 활용 필기(12) - 순위 계산 (0) 2020.05.05 [한기교] SQL 활용 필기(11) - 집합연산자, 집단연산자 (0) 2020.05.04 [한기교] SQL 활용 필기(10) - 중첩 질의문 (0) 2020.05.04